Subconsultas correlacionadas
A diferencia de las subconsultas vistas anteriormente, las cuales pueden ejecutarse independientemente de la sentencia externa, las correlacionadas son subconsultas en las que se hace referencia a columnas de la consulta externa, ya que utilizan un valor externo para ejecutarse.
Por ejemplo, volviendo al ejemplo de una base de datos de administración de alumnos de una institución académica visto en el tema anterior, si tenemos una tabla alumnos y una tabla examenes_rendidos (una tabla intermedia entre alumnos y examenes, donde se almacenan las calificaciones).

Digamos que nos piden obtener los nombres y apellidos de los alumnos cuyo promedio general de calificaciones es mayor a 60.
Como se puede ver en el DER, los nombres están en la tabla alumnos y las calificaciones se encuentran en la tabla examenes_rendidos, por lo que, se podría utilizar un JOIN para resolver esta consulta. Pero en este caso, utilizaremos una subconsulta correlacionada.
1SELECT id_alumno, nombre, apellido FROM alumnos AS a2WHERE (3 SELECT avg(calificacion)4 FROM examenes_rendidos AS er5 WHERE er.id_alumno = a.id_alumno6) > 607ORDER BY apellido;Si observamos, la subconsulta utiliza el campo a.id_alumno en su cláusula WHERE, donde a es el alias que establecimos para la tabla alumnos en la consulta externa. Es decir que, desde la subconsulta estamos haciendo referencia a un campo de la tabla de la consulta externa. Más aún, estamos accediendo al registro que se está procesando en la consulta externa.
Esto quiere decir que se va a tomar cada posible registro de la consulta externa (cada registro de la tabla alumnos) para calcular el valor del promedio en la subconsulta y, si cumple con la condición, se añadirá al result-set.
Podemos escribir coloquialmente lo que hace la subconsulta.
1SELECT id_alumno, nombre, apellido FROM alumnos a2WHERE (<promedio de calificaciones del alumno actual>) > 603ORDER BY apellido;La subconsulta necesita de cada valor que se obtiene en la sentencia externa para obtener sus valores. Cuando MySQL no encuentra el valor indicado en la subconsulta, busca en la consulta directamente superior y así sucesivamente (recordemos que podemos tener más de una subconsulta anidada). Por este motivo la subconsulta correlacionada funciona.
MySQL evalúa las consultas desde adentro hacia afuera.
Por último, no es necesario incluir el campo que se va a utilizar en la subconsulta en la expresión de selección de la consulta externa. Bien podríamos haber indicado solo nombre y apellido.
Subconsulta correlacionada en la expresión de selección
Veamos otro ejemplo, también con la base de datos World. Esta vez vamos a usar la subconsulta en la expresión de selección de la consulta externa, es decir, como una columna más del result-set final.
En este caso queremos mostrar el nombre y población de las ciudades con más de 1.000.000 de habitantes. Y además queremos mostrar el nombre del país al que pertenece cada ciudad.
1SELECT city.Name, city.Population, (2 SELECT country.name FROM country3 WHERE country.Code = city.CountryCode4) AS Country5FROM city WHERE city.Population > 10000006ORDER BY city.Population DESC;Esta subconsulta correlacionada obtiene el nombre del país (siempre es un solo valor) para cada registro de city, de tal forma que podemos incluir ese result-set como una columna más de la consulta externa. Cada valor obtenido en la subconsulta se asociará al registro actual de la consulta externa.
Es conveniente darle un alias a la nueva columna (en este caso “Country”), de otra forma se usará de nombre a la subconsulta entera, lo cual es incómodo para la lectura.
Un ejemplo más complejo
Ahora que tenemos un mejor entendimiento de esta característica, veamos una consulta un poco más compleja.
Queremos obtener una lista con los nombres de todos los alumnos que se inscribieron en la materia “Filosofía” y su promedio de calificaciones en la materia.
El DER completo de la base de datos es el siguiente:
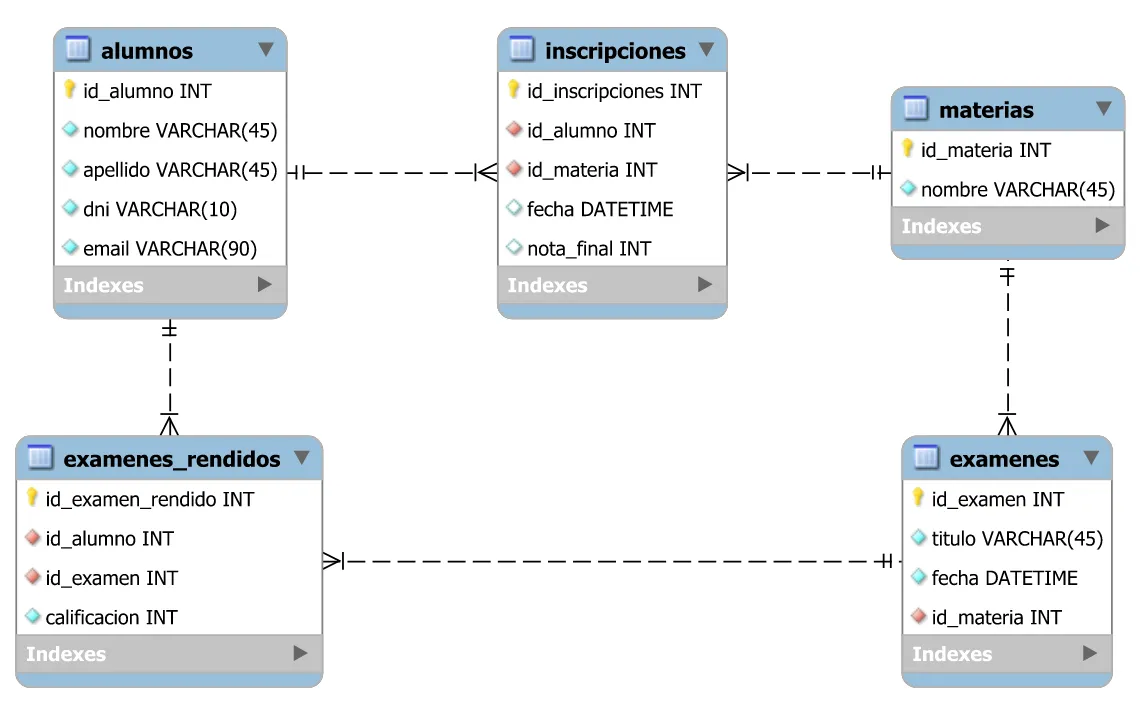
El DER representa la organización de los datos de la institución académica, donde, los alumnos pueden inscribirse a una o más materias y cada materia tiene distintos exámenes.
Esta consulta es compleja debido a que en necesario cruzar datos de varias tablas a la vez.
Primero, debemos obtener los nombres de los alumnos de la tabla alumnos, el promedio de la tabla examenes_rendidos, pero solo los que correspondan a exámenes de la materia “Filosofía”, y también debemos acotar los alumnos a solo los inscriptos en “Filosofía”.
Vamos a dar una solución usando 2 subconsultas correlacionadas (una dentro de otra), una subconsulta no correlacionada y un JOIN.
La consulta resultante es la siguiente:
1SELECT nombre, apellido, (2 SELECT AVG(calificacion)3 FROM examenes_rendidos AS er4 WHERE er.id_alumno = a.id_alumno5 AND er.id_examen IN (6 SELECT id_examen7 FROM examenes8 WHERE id_materia = i.id_materia9 )10) AS promedio11FROM alumnos AS a12INNER JOIN inscripciones AS i ON a.id_alumno = i.id_alumno13WHERE i.id_materia = (14 SELECT id_materia15 FROM materias16 WHERE nombre = "Filosofía"17);Vamos a explicar el razonamiento tras esta consulta.
En primer lugar, la consulta externa debe incluir un JOIN de alumnos con inscripciones ya que debemos tomar solo los inscriptos en “Filosofía”. En este caso, como inscripciones no almacena los nombres de las materias y solo contamos con el nombre, podemos usar una subconsulta no correlacionada para obtener el id de la materia, en lugar de realizar un JOIN más con materias (pero bien podríamos usar un JOIN con el mismo efecto).
Entonces la consulta externa quedará como sigue:
1SELECT nombre, apellido, <promedio>2FROM alumnos AS a3INNER JOIN inscripciones AS i ON a.id_alumno = i.id_alumno4WHERE i.id_materia = (5 SELECT id_materia6 FROM materias7 WHERE nombre = "Filosofía"8);Donde <promedio> es la otra subconsulta que calcula el promedio de cada alumno.
Ahora veamos cómo resolver la obtención del promedio de calificaciones de la materia, para cada alumno, a través de una subconsulta.
La subconsulta debe ejecutarse sobre la tabla examenes_rendidos ya que allí se almacenan las calificaciones. Las dos claves foráneas de esta tabla son id_alumno e id_examen, y debemos utilizarlas para restringir los resultados solo a las calificaciones de la materia “Filosofía”.
Al id del alumno podemos obtenerlo directamente de la consulta externa. Pero para obtener el id del examen debemos consultar, primero, la tabla examenes, ya que esta nos indica a cuál materia corresponde el examen y luego a la tabla materias ya que en esta están sus nombres, que es el valor con el que contamos.
Para esto podríamos realizar otro JOIN en la subconsulta con la tabla examenes. Pero, como en la consulta externa ya realizamos un JOIN con inscripciones para obtener el id de la materia, podemos reutilizar ese id en la subconsulta correlacionada.
De esta forma, la subconsulta que calcula el promedio quedará de la siguiente forma:
1SELECT AVG(calificacion)2FROM examenes_rendidos AS er3WHERE er.id_alumno = a.id_alumno4AND er.id_examen IN (5 SELECT id_examen6 FROM examenes7 WHERE id_materia = i.id_materia8);Donde a.id_alumno se toma de la consulta externa inmediatamente superior e i.id_materia, ya que se encuentra en una subconsulta de una subconsulta, se toma de 2 niveles superiores a la subconsulta en la que se la utiliza.
De esta manera, queda conformada la consulta que obtiene los datos solicitados.
A los fines de una comparación, esta consulta se puede resolver usando solo JOINs entre las 5 tablas, de la siguiente manera:
1SELECT a.nombre, a.apellido, AVG(er.calificacion) AS promedio2FROM alumnos a3INNER JOIN inscripciones i ON a.id_alumno = i.id_alumno4INNER JOIN examenes_rendidos er ON er.id_alumno = a.id_alumno5INNER JOIN examenes e ON er.id_examen = e.id_examen6INNER JOIN materias m ON m.id_materia = e.id_materia7WHERE m.nombre = "Filosofía"8GROUP BY a.nombre, a.apellido;Notar que en esta última consulta es necesario utilizar una cláusula GROUP BY ya que la función de agregación se ejecuta en la misma consulta, a diferencia de la consulta anterior en la que la función de agregación se ejecuta en la subconsulta, obteniendo solo ese valor (por lo que no necesita la cláusula GROUP BY).
Extra
Tablas derivadas
Una tabla derivada es una expresión que genera una tabla (dinámica) dentro del ámbito de la cláusula FROM de una consulta. Es común usar una subconsulta como una tabla derivada. Por ejemplo:
1SELECT ... FROM <subconsulta> [AS] nombre_tabla_derivada;Los nombres de las columnas de la expresión de selección de la subconsulta se usan en la consulta externa, por lo tanto, deben tener nombres únicos. Por ejemplo:
1SELECT c1, c2, c3 FROM (2 SELECT tb1 AS c1, c2, tb2 AS c33 FROM tabla_base14) AS tabla_derivada1;En este ejemplo, la tabla base tabla_base1 tiene (al menos) los campos tb1, c2 y tb2. En la subconsulta que genera la tabla derivada, renombramos tb1 a c1 y tb2 a c3 (c2 se mantiene con el mismo nombre). Posteriormente, en la consulta externa usamos los nombres c1, c2 y c3, ya que son los nombres indicados en la tabla derivada.
Observar que, al revés de lo que se daba en las subconsultas correlacionadas, aquí se utilizan los nombres de los campos de una subconsulta en la consulta externa. Es decir, se usa la tabla derivada (generada en el momento) como si se tratase de una tabla normal.
Este tipo de consultas también puede ser todo lo complicada que necesitemos, ya que la tabla derivada es una subconsulta más, y puede contener otras subconsultas, JOINs, etc.